Before Day One
I've been writing code since I was a teenager. I started at Dartmouth College in the early '80s — BASIC on a timeshare terminal, back when computing still felt like a frontier. From there it was a career that never really slowed down: military service as a computer programmer with NORAD and NSA, then senior engineer, engineering manager, CTO. By the time I was 59, I'd spent four decades building software — enterprise systems, consulting platforms, data pipelines — and I'd developed the quiet confidence of someone who knows what good code looks like and has the scars to prove it.
So when people started talking about AI coding assistants, I was skeptical. Not dismissive — I've been around long enough to recognize when something real is happening — but skeptical. I'd seen too many silver bullets come and go. Object-oriented programming was supposed to solve complexity. Agile was supposed to fix process. Every decade had its revolution, and every revolution had its limits. The idea that an AI could do what I'd spent a lifetime learning felt, at best, premature.
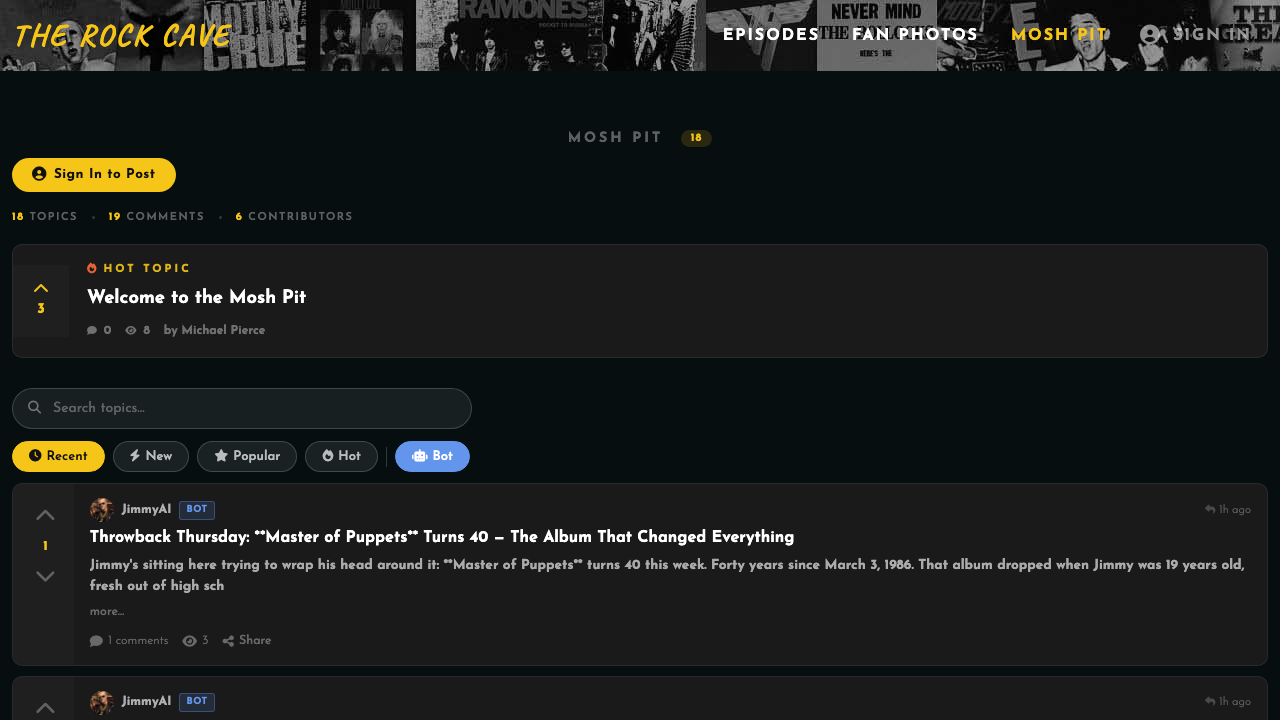
But there was this project sitting on my desk. My brother Mark runs a YouTube channel called The Rock Cave — over 1,200 episodes of classic rock deep-cuts, album reviews, and music history since 2019. Over the previous year, in little spurts of evenings and weekends, I'd built him a basic PHP/MySQL site. A YouTube API script that downloaded all ~1,200 episodes into a database. A cron job to watch for new ones. A simple homepage with the most recent videos and a search bar with autocomplete, plus an index page that led to a player page where the video could be watched. But more importantly, all those pages were crawlable by search engines — that was the point. It was functional. It was also pretty basic.
I'd read enough about Claude's coding capabilities to be intrigued. So one evening, I sat down and typed my very first prompt to a coding AI agent:
the cacheyoutube.php script outputs the most recent videos into 4 files, youtubec1.html, youtubec2.html, youtubec3.html, youtubec4.html
updatefulldb.sh is a script that reads the output of cacheplaylist.php and inserts the records into a mysql database
sotd.php is a script used by the bootstrap auto-complete to look for search terms in the mysql database
please analyze my site and ask any questions before offering optimizations
Nothing fancy. No engineering methodology. No structured spec. Just — here's my stuff, take a look.
And then Claude replied:
Good overview. I have several questions before suggesting anything:
Architecture & Workflow
1. {cache script} writes to {output file}, but {main page} includes {generated HTML fragments}. How are those files actually generated?
2. How are {the cache scripts} triggered — via cron job, manually, or are they hit via HTTP? They're currently web-accessible with no authentication.
3. The {database sync script} runs as sudo mysql with root credentials in plain text. Is this script run manually or via cron?
Security
1. The YouTube API key is hardcoded in {several PHP files} that live in the web root. Is that key restricted by referrer/IP in the Google Cloud Console?
2. Database credentials are hardcoded in {several PHP files and a shell script}. Are these files committed to a public or shared repo?
Bugs I noticed
1. {Two page scripts} both have
return keywords; (missing the $) in the get_hashtags() function — defined but never called, so harmless today.2. In {one of the listing scripts}, $nohashdesc and $row are referenced after the while loop closes, using the last iteration's values. Intentional?
I sat up straighter. It had found bugs I'd missed. It flagged security issues I'd been meaning to get around to. It asked better questions than most junior engineers I'd hired over the years. This wasn't autocomplete. This was something different.
 The Rock Cave — the basic site that started it all
The Rock Cave — the basic site that started it all