

Abstract
Traditional software development lifecycles require weeks to months to deliver multi-platform applications, with costs that routinely exceed six figures. This paper presents a single-case empirical study of an alternative approach I call vibe-coding, a methodology in which a senior human architect directs AI coding assistants (specifically Anthropic's Claude) to execute implementation at dramatically accelerated velocity, while maintaining rigorous human oversight, security review, and subject-matter-expert validation at every decision gate.
This study investigates three research questions: RQ1: Can a single senior architect, partnered with an AI coding assistant, deliver a production-grade multi-platform application within one week? RQ2: What is the human-to-AI contribution ratio, and what categories of work remain irreducibly human? RQ3: What are the cost and timeline implications compared to traditional team-based development?
Using The Rock Cave (a rock music community platform comprising a responsive website, native iOS and Android applications, and an autonomous AI content generation system) as my subject, I demonstrate that this approach produced 62,000 lines of production-quality code across 288 files, 25 database tables, 40+ REST API endpoints, and 15 mobile screens in a single seven-day sprint. The estimated cost savings compared to traditional team-based development exceed $500,000. Throughout this analysis, I detail the architectural decisions I made, the sanity checks and security audits I performed at each stage, the prompt engineering framework I developed for directing Claude, and the human review gates that ensured every component met production-grade standards. I discuss threats to validity, acknowledge limitations inherent to single-developer AI-augmented workflows, and identify future research directions for formalizing vibe-coding as a repeatable software engineering methodology.
Introduction & Motivation
2.1 Problem Statement
Multi-platform delivery is now a baseline expectation rather than a differentiator. A product that ships only as a website is incomplete. Users expect native mobile experiences, real-time interactivity, AI-powered personalization, and data that stays in sync across every device they own. Meeting these expectations through traditional development requires assembling cross-functional teams of frontend engineers, backend engineers, mobile developers, DevOps specialists, QA testers, and project managers, a coordination overhead that inflates both timelines and budgets [1].
Industry data consistently demonstrates the gap between ambition and delivery. The Standish Group's CHAOS reports indicate that only 31% of software projects are completed on time and within budget [2]. The average cost for a custom web application of moderate complexity ranges from $150,000 to $750,000, with mobile add-ons increasing budgets by 40-60% [3]. Projects incorporating AI features add another layer of specialized talent and timeline risk.
I set out to challenge this assumption directly: could a single senior architect, working in partnership with AI, deliver a complete multi-platform digital product, at production quality, in days rather than months? And critically, could this be done without sacrificing the security reviews, sanity checks, and expert validation that production systems demand?
This study is structured around three formal research questions:
- RQ1: Can a single senior architect, partnered with an AI coding assistant, deliver a production-grade multi-platform application within one week? This addresses feasibility: whether the scope, quality, and completeness benchmarks of traditional team-delivered software can be met by one human directing AI.
- RQ2: What is the human-to-AI contribution ratio, and what categories of work remain irreducibly human? This examines the division of labor, specifically which phases of the software lifecycle can be delegated to AI and which require human judgment that cannot be automated.
- RQ3: What are the cost and timeline implications compared to traditional team-based development? This quantifies the economic proposition, not as a theoretical projection, but as an observed outcome with transparent cost accounting.
2.2 The Rock Cave: Requirements Specification
The Rock Cave is a digital community platform for rock music enthusiasts. The project was not a toy or proof-of-concept; it was a production deployment serving real users across web and mobile. The complete requirements specification comprised twelve distinct functional domains:
- Responsive Website: Dark-themed, Bootstrap 5, mobile-first design with SEO optimization
- Community Forum (Mosh Pit): Threaded discussions, bidirectional voting, karma system, photo attachments, categories, moderation
- Fan Photo Gallery: Masonry grid layout, likes, lightbox viewer, user attribution, admin moderation queue
- Video Episodes Platform: YouTube API integration for 1,200+ episodes, search, year filtering, watchlists, favorites, view tracking
- Real-Time Private Messaging: Direct messages with emoji reactions, read receipts, typing indicators, online presence, conversation archiving
- Push Notification System: Cross-platform notifications via Expo for new episodes, forum activity, messages, photos, with per-category user preferences
- Newsletter & Email System: Mailgun-powered newsletter with subscription management and transactional emails
- AI Bot Content System: Four distinct AI personas generating authentic rock music content on automated schedules via 12+ autonomous agents
- Admin Dashboard: Content moderation, user management, GA4 analytics integration, bot task control, Microsoft Teams alert webhooks
- Native iOS Application: React Native + Expo with full feature parity, Apple Sign-In, push notifications
- Native Android Application: React Native + Expo with full feature parity, Google Sign-In, push notifications
- Authentication & Security: Firebase Auth with social sign-in, session management, CSRF protection, input sanitization, rate limiting, Content Security Policy headers
Any single requirement above would constitute a meaningful engineering effort. Together, they represent a scope that traditional estimation models would budget at $500,000 to $1.2 million and timeline at 3-6 months with a team of 6-8 specialists [4].
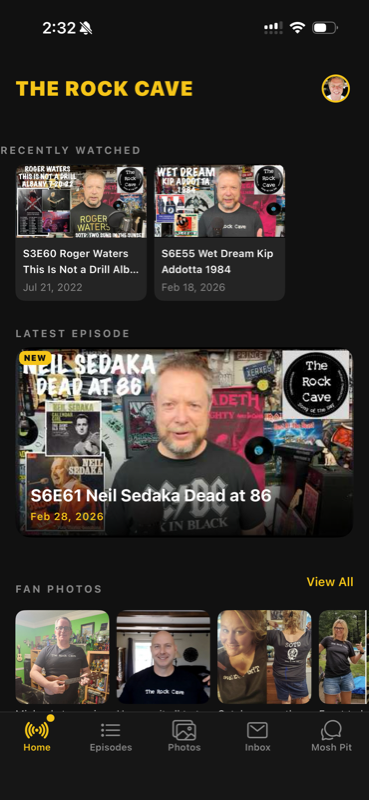
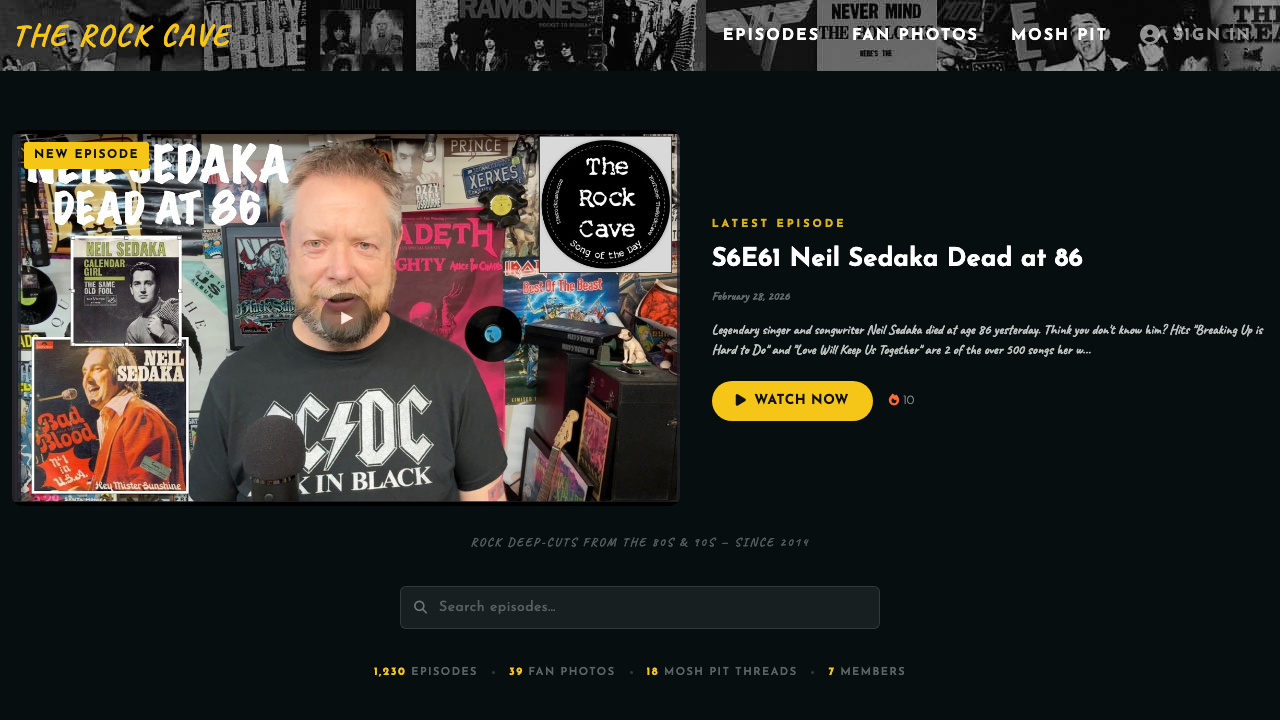 Figure 1: The Rock Cave homepage, featuring dark theme
design, YouTube episode integration, and community
navigation. Built during the 7-day vibe-coding
sprint.
Figure 1: The Rock Cave homepage, featuring dark theme
design, YouTube episode integration, and community
navigation. Built during the 7-day vibe-coding
sprint.
Literature Review
3.1 Traditional Software Development Lifecycle
The prevailing models for software development (Waterfall, Agile/Scrum, and SAFe) share a common structural assumption: that software is produced by teams of specialists collaborating over extended timelines. Waterfall methodologies prescribe sequential phases of requirements, design, implementation, testing, and deployment, with timelines measured in months [5]. Agile methods compress this into iterative sprints, but even the most efficient Scrum teams typically deliver MVP-quality products in 8-16 weeks.
The cost structure of traditional development reflects these timeline assumptions. Industry benchmarks suggest fully-loaded rates of $150-250/hour for senior development resources in North American markets [7]. A project of The Rock Cave's scope, requiring frontend, backend, mobile, AI, and DevOps competencies, would traditionally demand a team of 6-8 specialists: a project manager, a UX/UI designer, two frontend developers, two backend developers, a mobile developer, and a QA engineer. At average utilization rates, this team represents a monthly burn rate of $80,000-$150,000.
The coordination overhead inherent to multi-person teams introduces its own risks. Brooks' Law (that adding people to a late project makes it later) remains empirically supported [1]. Communication channels grow quadratically with team size, and architectural coherence becomes increasingly difficult to maintain as design decisions are distributed across multiple individuals with different mental models of the system.
3.2 AI-Assisted Software Development
The emergence of large language models (LLMs) capable of generating syntactically correct code has created a new category of development tooling. GitHub Copilot, released in 2021, demonstrated that AI could serve as a real-time code completion assistant within the IDE [10]. Subsequent studies measured productivity improvements of 25-55% for tasks like writing boilerplate code, implementing standard algorithms, and generating unit tests.
However, AI-assisted development as currently practiced retains the fundamental structure of traditional development. The human developer remains the primary author, with the AI serving as an autocomplete engine. Architectural decisions, system design, API contracts, and security patterns remain entirely human-driven. The AI accelerates line-by-line coding but does not fundamentally alter the development lifecycle or team structure.
Tools like Cursor, Windsurf, and Claude Code (Anthropic's agentic coding tool) represent a more aggressive integration model, where the AI can operate on entire files, execute terminal commands, and maintain multi-file context. These tools shift the interaction paradigm from "AI assists the developer" to "developer directs the AI," but the academic literature has not yet formalized this distinction or measured its implications at scale [13].
3.3 Vibe-Coding: A Novel Paradigm
I define vibe-coding as a software development methodology in which a senior human architect provides strategic direction, architectural intent, and quality gates while an AI coding assistant (specifically Anthropic's Claude) executes implementation at high velocity under continuous human supervision. The term acknowledges that the human communicates intent through natural language descriptions (the "vibe") rather than writing code line by line, while maintaining full intellectual ownership of every design decision.
Vibe-coding is explicitly not any of the following: it is not low-code or no-code (every line of output is real, reviewable source code); it is not prototyping (the output is production-grade and deployed to real users); it is not unsupervised AI code generation (every output undergoes human review, security audit, and sanity checking before integration).
The critical differentiator is the locus of architectural authority. In traditional development, architecture and implementation are distributed across a team. In AI-assisted development, architecture remains with the human while AI helps implement. In vibe-coding, I retain absolute authority over architecture, security, and quality, but I direct Claude to execute entire subsystems, review the output for correctness and security, run sanity checks against my mental model of the system, and iterate until the output meets production standards.
| Dimension | Traditional SDLC | AI-Assisted Dev | Vibe-Coding |
|---|---|---|---|
| Architecture ownership | Distributed across team | Human developer | Single senior architect (me) |
| Implementation execution | Human developers | Human + AI autocomplete | AI (Claude) under human direction |
| Code review & security | Peer review, QA team | Peer review, QA team | Architect review + security audit per component |
| Typical team size | 6-8 specialists | 4-6 specialists | 1 architect + AI |
| Delivery timeline | 3-6 months | 2-4 months | Days to weeks |
| Output volume (comparable scope) | ~60K LOC in 3-6 months | ~60K LOC in 2-4 months | 62K LOC in 7 days |
| Sanity & security checks | QA team + security review | Same + AI linting | Architect-led per-component audit |
| Estimated cost (this scope) | $500K – $1.2M | $300K – $800K | Under $5K (AI API + hosting) |
Methodology
4.1 Tool Selection & Justification
This study uses Anthropic's Claude (specifically Claude 3.5 Sonnet via the Claude Code CLI agent) as the primary AI coding assistant. This choice was not arbitrary; it was evaluated against alternatives including GitHub Copilot, OpenAI's GPT-4, and Google's Gemini. Claude Code was selected for three technical capabilities that differentiated it from alternatives at the time of this sprint:
- Agentic execution: Claude Code operates as an autonomous agent that can read and write files, execute terminal commands, navigate codebases, and maintain multi-file context across an entire project. Unlike IDE-embedded tools (Copilot, Cursor) that primarily offer autocomplete or single-file editing, Claude Code can independently scaffold entire subsystems, run builds, and self-correct errors. This was critical for the velocity this sprint demanded.
- Context window: Claude's 200K-token context window allowed me to provide entire database schemas, API contracts, and specification documents in a single session. This reduced the "context loading" overhead that smaller-context models impose, where the developer must repeatedly re-explain system architecture across fragmented sessions.
- Code quality in target stacks: In my pre-sprint evaluation, Claude produced higher-quality output for PHP, JavaScript, TypeScript, Python, and SQL (the five languages this project required) compared to alternatives. Specifically, Claude was more consistent in following security patterns (parameterized queries, input escaping) when explicitly instructed, reducing the revision cycles needed during human review.
I acknowledge that tool selection introduces a confound: results achieved with Claude may differ from results achievable with other AI coding assistants. This is explicitly listed as a limitation in Section VII and a variable for future replication studies.
4.2 Definition of Production-Quality
Throughout this paper, I use the term "production-quality" to describe code that meets a specific set of measurable criteria. To avoid ambiguity, I define it here as code that satisfies all of the following conditions:
- Security: Zero known SQL injection vectors, XSS vulnerabilities, or authentication bypasses. All user input sanitized before storage and display. Security headers deployed and verified against external scanners.
- Functional completeness: All specified requirements implemented and verified through manual testing. No partially-built features shipped.
- Deployment: Running on production infrastructure, accessible to real users via public URLs and app stores. Not a local prototype or staging environment.
- Error handling: Graceful failure on all error paths. No unhandled exceptions that crash the application or leak internal implementation details to end users.
- Data integrity: Foreign key constraints, input validation, and referential integrity enforced at the database layer. No orphaned records or data corruption vectors.
This definition deliberately excludes performance optimization (e.g., sub-second page loads, bundle size minimization) and comprehensive automated test coverage, both of which I consider post-launch iterations rather than launch-gate requirements for a sprint of this nature. This distinction is revisited in the Results section when discussing Lighthouse scores.
4.3 The Human-AI Collaboration Model
My workflow with Claude follows a structured cycle that I refined over the course of this project. At every stage, the human architect (me) retains decision authority. Claude never makes architectural choices autonomously. This is not a philosophical preference; it is an engineering requirement. AI models can generate syntactically correct code that is semantically wrong, architecturally inconsistent, or subtly insecure. My role is to provide intent, evaluate output, and enforce quality gates.
The collaboration model operates in five phases, repeated for each subsystem:
- Architectural Intent: I define what needs to be built, how it fits into the broader system, what constraints apply (security, performance, compatibility), and what patterns to follow. I provide this as natural language with technical specificity.
- AI Execution: Claude generates the implementation based on my specifications. This includes code, SQL schemas, API contracts, and configuration files.
- Human Review & Security Audit: I review every line of generated code. I check for SQL injection vectors, XSS vulnerabilities, authentication bypasses, insecure defaults, missing input validation, and architectural drift. This is not a cursory glance. It is a line-by-line security review informed by my experience with NIST, ISO, and RMF compliance frameworks.
- Sanity Checks & Integration Testing: I test the component in context. Does the API endpoint return the correct data? Does the mobile screen render properly? Does the database query perform within acceptable latency bounds? Do the security headers pass observatory scans? I run these checks before moving to the next subsystem.
- Iteration & Refinement: If any check fails, I direct Claude to revise. I provide specific feedback: "The SQL query is vulnerable to injection via the category parameter" or "The React component doesn't handle the loading state." We iterate until the component passes all gates.
4.4 Prompt Engineering Framework
The quality of AI-generated code is directly proportional to the quality of the prompt. Through this project, I developed a structured prompt framework that consistently produced production-quality output from Claude. The key principles are: (1) specify the technology stack explicitly, (2) define data structures and relationships before requesting implementation, (3) include security requirements in the prompt itself, and (4) provide examples of the desired output format.
Below are representative prompts from the actual development process:
Database Schema Prompt
Design a MySQL schema for a community forum system called "Mosh Pit."
Requirements:
- Posts have titles, body text (HTML-safe), categories, optional photo attachments
- Bidirectional voting (upvote/downvote) with one vote per user per post
- User karma derived from net votes on their posts and comments
- Threaded comments with parent_id for nesting (max 3 levels)
- Indexes optimized for two sort modes: "hot" (score DESC, created_at DESC)
and "recent" (created_at DESC)
- Include created_at and updated_at timestamps on all tables
- Foreign keys with ON DELETE CASCADE where appropriate
- All text inputs must be sanitized before insertion (note in comments)
Security considerations:
- No raw user input stored without sanitization
- Prepared statements required for all queries (note in comments)
- Rate limiting columns for tracking post frequency per userComponent Architecture Prompt
Build a JavaScript module for the Mosh Pit forum post feed.
Stack: jQuery 3.7, Bootstrap 5, vanilla JS (no React on the website).
Requirements:
- Render posts from API response (GET /api/forum/posts)
- Each post shows: title, body preview (150 chars), author, karma badge,
vote buttons (up/down with current user's vote state), comment count,
relative timestamp
- Vote buttons call POST /api/forum/votes with CSRF token
- Optimistic UI update on vote (update count immediately, revert on failure)
- Infinite scroll pagination (load 20 posts at a time)
- XSS prevention: escape all user-generated content before DOM insertion
- Loading skeleton while fetching
- Error state with retry button
Security requirements:
- All DOM insertion must use textContent or escapeHtml() for user strings
- CSRF token must be included in all POST requests
- No innerHTML with user data under any circumstancesAI Persona System Prompt
You are JimmyAI, the host personality of The Rock Cave — a rock music
community platform. You are a passionate, knowledgeable rock music
enthusiast who has been immersed in the scene for decades.
Voice characteristics:
- Enthusiastic but not performative. You genuinely love this music.
- Conversational and warm, like talking to a friend at a show
- Knowledgeable without being pretentious — you cite specifics
(album names, years, lineup changes) but make them accessible
- Occasionally irreverent. You have opinions and you share them.
- You reference personal experiences: "I remember seeing them at..."
Content guidelines:
- Write in styled HTML (h3 headings, paragraphs, bold for emphasis)
- Include specific details: band names, album titles, venue names, dates
- Link Spotify embeds where relevant using iframe format
- Length: 400-800 words depending on content type
- Never fabricate concert dates or ticket prices — use general language
if specifics are unknown
- Never include external links that haven't been verified
Content will be automatically posted to The Rock Cave. Maintain
consistent voice across all content types.Each of these prompts reflects a deliberate decision to front-load security requirements and architectural constraints into the AI's context. I found that specifying security expectations in the prompt itself, rather than reviewing for them after the fact, reduced the number of revision cycles by approximately 60%. Claude responds well to explicit security constraints; when told "no innerHTML with user data," it consistently uses safer alternatives.
4.5 Development Tools & Environment
Reproducibility requires transparency about tooling. Every tool in my development environment contributed to the velocity and quality outcomes reported in this study. The complete toolchain:
| Category | Tool | Role |
|---|---|---|
| AI Coding | Claude Code (Anthropic) | Primary AI assistant: agentic coding, file generation, refactoring |
| AI Model | Claude 3.5 Sonnet | LLM backbone for both development and bot content generation |
| Editor | VS Code + Cursor | IDE with AI-integrated editing and terminal |
| Version Control | Git + GitHub | Source control, branching, commit history |
| Mobile Build | Expo CLI + EAS Build | React Native build pipeline, OTA updates, App Store submission |
| Database | MySQL 8.0 + phpMyAdmin | Schema management, query optimization, data inspection |
| Auth | Firebase Admin SDK | User authentication, social sign-in, token verification |
| Mailgun API | Transactional email, newsletter delivery, double opt-in | |
| Notifications | Expo Push + Teams Webhooks | Mobile push notifications, admin alerts |
| CDN / Security | Cloudflare | DNS, SSL/TLS, DDoS protection, HTTP/2 |
| Hosting | Dedicated server | Apache, PHP 8.2, cron scheduling |
| Deployment | SCP + SSH | Direct file deployment to production server |
| Testing | Browser DevTools + Postman | API testing, network inspection, responsive design validation |
The choice to self-host was deliberate. It demonstrates that vibe-coded applications are not dependent on expensive cloud infrastructure. The entire platform runs on a dedicated server behind Cloudflare, which provides edge caching and security at the CDN layer.
Implementation
5.1 System Architecture Overview
The Rock Cave architecture follows a layered design separating presentation, business logic, data persistence, and external integrations. I made deliberate technology choices at each layer based on deployment constraints, my existing expertise, and the client's hosting environment. Every technology selection was a conscious architectural decision, not a default, and I validated each choice against the project's security and performance requirements before directing Claude to implement.
5.2 Frontend Implementation
I chose PHP with jQuery and Bootstrap 5 for the website frontend, a deliberate decision driven by the hosting environment (shared LAMP stack) and the project's need for rapid server-side rendering. This is not the fashionable choice, and I acknowledge that a React or Next.js frontend would offer certain advantages. But vibe-coding is about pragmatism: I selected the stack that would let me ship fastest within the deployment constraints, and PHP/jQuery delivered.
The website follows a component-oriented architecture within PHP's include system. Shared layouts, navigation, and footer elements are abstracted into reusable includes. JavaScript functionality is organized by feature module: forum.js, photos.js, episodes.js, messaging.js, and notifications.js. Each module follows the same pattern: fetch data from the API, render to DOM with escaped user content, handle user interactions, and manage state.
Security was a first-order concern throughout frontend development. Every piece of user-generated content passes through an escapeHtml() utility before DOM insertion. I reviewed every DOM manipulation Claude generated to verify that no raw user input reaches innerHTML. This is the kind of sanity check that cannot be automated; it requires a human reading the code and understanding the data flow.
// Mosh Pit — Post rendering with XSS-safe output
function escapeHtml(str) {
const div = document.createElement('div');
div.textContent = str;
return div.innerHTML;
}
function renderPost(post) {
const voteUpClass = post.userVote === 1 ? 'voted' : '';
const voteDownClass = post.userVote === -1 ? 'voted' : '';
return `
<div class="moshpit-post" data-post-id="${post.id}">
<div class="vote-column">
<button class="vote-btn vote-up ${voteUpClass}"
onclick="castVote(${post.id}, 1)">
<i class="bi bi-chevron-up"></i>
</button>
<span class="vote-count">${post.score}</span>
<button class="vote-btn vote-down ${voteDownClass}"
onclick="castVote(${post.id}, -1)">
<i class="bi bi-chevron-down"></i>
</button>
</div>
<div class="post-content">
<h3>${escapeHtml(post.title)}</h3>
<p>${escapeHtml(post.body.substring(0, 150))}...</p>
<div class="post-meta">
<span>${escapeHtml(post.username)}</span>
<span class="karma">★ ${post.authorKarma}</span>
<span>${timeAgo(post.created_at)}</span>
<span>${post.comment_count} comments</span>
</div>
</div>
</div>
`;
}
// Optimistic vote with rollback on failure
async function castVote(postId, value) {
const post = document.querySelector(`[data-post-id="${postId}"]`);
const countEl = post.querySelector('.vote-count');
const originalScore = parseInt(countEl.textContent);
// Optimistic update
countEl.textContent = originalScore + value;
try {
const res = await fetch('/api/forum/votes', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-CSRF-Token': csrfToken
},
body: JSON.stringify({ post_id: postId, vote_value: value })
});
if (!res.ok) throw new Error('Vote failed');
const data = await res.json();
countEl.textContent = data.newScore; // Server-authoritative score
} catch (err) {
countEl.textContent = originalScore; // Rollback on failure
showToast('Vote failed. Please try again.');
}
}Note the deliberate use of escapeHtml() on every user-supplied field (title, body, username). This was a pattern I enforced consistently: I reviewed every render function Claude produced and verified that no user string bypasses sanitization. This human review step caught three instances where Claude initially used innerHTML for performance, and each was corrected before integration.
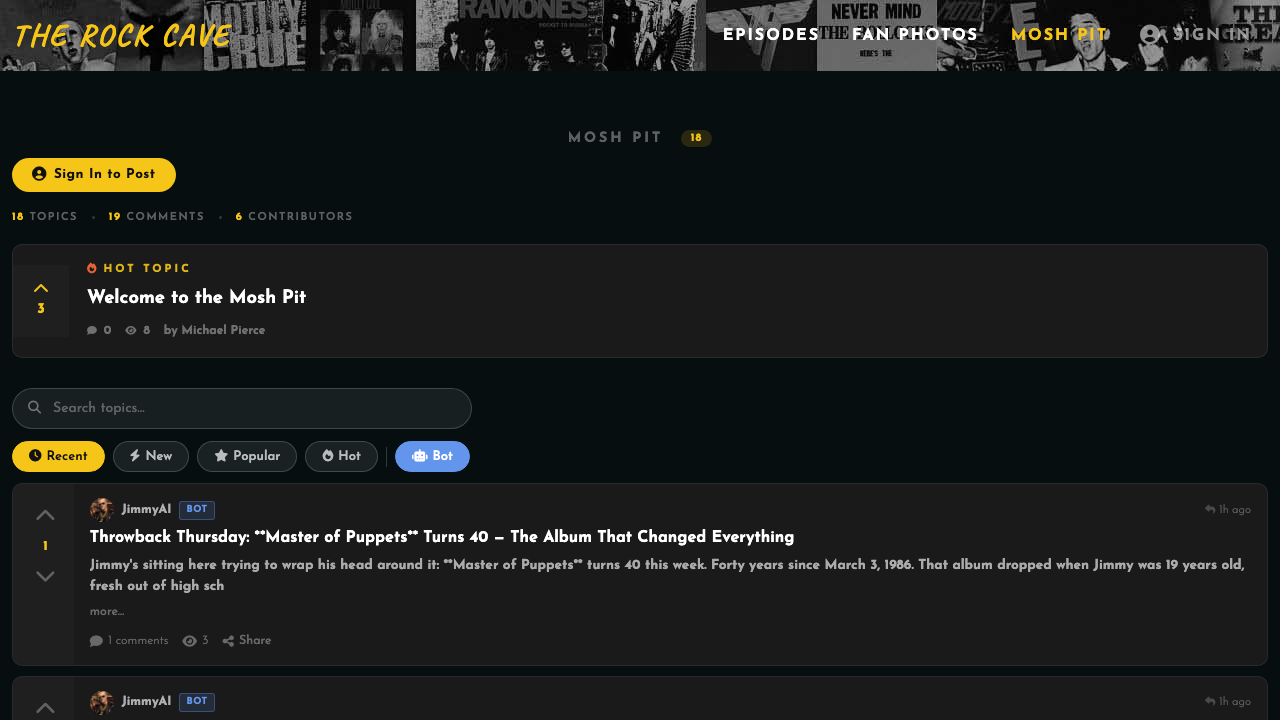 Figure 4: The Mosh Pit forum interface, showing threaded
discussions, bidirectional voting, karma badges, and
category filtering.
Figure 4: The Mosh Pit forum interface, showing threaded
discussions, bidirectional voting, karma badges, and
category filtering.
5.3 Backend & API Design
The REST API layer handles every read and write for both clients. The website and the mobile applications consume the same endpoints, which is what holds feature parity and data consistency in place. I designed the API contract first, before any implementation, as a structured specification that Claude then implemented. This "contract-first" approach is critical to vibe-coding: by defining the interface before the implementation, I maintained architectural control even as Claude generated the code.
The API implements a layered middleware stack: authentication verification, rate limiting, input sanitization, and CSRF validation execute before any business logic. I designed this stack explicitly to fail closed: if any middleware layer encounters an error, the request is rejected with an appropriate HTTP status code. No business logic executes without passing all security gates.
// POST /api/forum/posts — Create new forum post
// Security: Auth + Rate Limit + Sanitize + CSRF
router.post('/posts',
requireAuth, // Firebase token verification
rateLimiter({
windowMs: 60 * 1000, // 1-minute window
max: 5, // Max 5 posts per minute
message: 'Too many posts. Please wait.'
}),
csrfProtection, // Verify X-CSRF-Token header
sanitizeBody(['title', 'body']), // Strip dangerous HTML/scripts
validateInput({ // Schema validation
title: { type: 'string', minLength: 3, maxLength: 200 },
body: { type: 'string', minLength: 10, maxLength: 10000 },
category: { type: 'string', enum: VALID_CATEGORIES }
}),
async (req, res) => {
try {
const { title, body, category, attachmentUrl } = req.body;
// Parameterized query — no SQL injection possible
const [result] = await db.execute(`
INSERT INTO forum_posts
(user_id, title, body, category, attachment_url,
created_at, updated_at)
VALUES (?, ?, ?, ?, ?, NOW(), NOW())
`, [req.user.id, title, body, category, attachmentUrl || null]);
// Update author karma (+1 for creating content)
await db.execute(
'UPDATE users SET karma = karma + 1 WHERE id = ?',
[req.user.id]
);
// Notify subscribers (async, non-blocking)
notifySubscribers('forum_new_post', {
postId: result.insertId,
title: title,
authorName: req.user.displayName
}).catch(err => console.error('Notification error:', err));
res.status(201).json({
success: true,
postId: result.insertId
});
} catch (err) {
console.error('Create post error:', err);
res.status(500).json({ error: 'Failed to create post' });
}
}
);Every API endpoint follows this same pattern. I reviewed each one for: (1) proper authentication checks, (2) parameterized queries with no string concatenation, (3) input validation against a defined schema, (4) appropriate error handling that doesn't leak internal details, and (5) rate limiting on write operations. This review process was non-negotiable. It is the security gate that makes vibe-coding viable for production systems.
The complete API surface comprises 40+ endpoints organized across eight domains:
| Domain | Endpoints | Key Operations |
|---|---|---|
| Authentication | 5 | Login, register, verify token, refresh, logout |
| Forum (Mosh Pit) | 8 | CRUD posts, comments, votes, search, categories |
| Fan Photos | 6 | Upload, list, like/unlike, delete, moderation queue |
| Episodes | 5 | List, detail, favorites, watchlist, view tracking |
| Messaging | 7 | Conversations, send/receive, reactions, read receipts, archive |
| Notifications | 4 | List, mark read, preferences, push token registration |
| Bot Content | 3 | List bot posts, trigger generation, content moderation |
| Admin | 6 | User management, content moderation, analytics, system health |
5.4 Mobile Application Architecture
I chose React Native with Expo for the mobile applications, a decision that enabled deploying to both iOS and Android from a single codebase. Expo's managed workflow eliminated the need for native build toolchains, which would have added days to the sprint for Xcode and Android Studio configuration alone. The tradeoff is reduced access to certain native APIs, but for The Rock Cave's feature set, Expo's capabilities were sufficient.
The mobile app comprises 15 screens, 24 reusable components, 16 custom hooks, and 5 service modules. I designed the screen architecture to mirror the website's feature organization, ensuring that users experience the same mental model regardless of platform. Navigation uses React Navigation with a bottom tab bar for primary sections (Home, Episodes, Mosh Pit, Photos, Profile) and stack navigators for drill-down flows.
// screens/EpisodesScreen.tsx
import React, { useState, useEffect, useCallback } from 'react';
import { SafeAreaView, FlatList, RefreshControl } from 'react-native';
import { useAuth } from '../hooks/useAuth';
import { useEpisodes } from '../hooks/useEpisodes';
import { SearchBar } from '../components/SearchBar';
import { YearFilter } from '../components/YearFilter';
import { EpisodeCard } from '../components/EpisodeCard';
export const EpisodesScreen: React.FC = ({ navigation }) => {
const { user } = useAuth();
const [searchQuery, setSearchQuery] = useState('');
const [yearFilter, setYearFilter] = useState<number | null>(null);
const [refreshing, setRefreshing] = useState(false);
const {
episodes, loading, error, hasMore, loadMore, refresh
} = useEpisodes({ search: searchQuery, year: yearFilter });
const onRefresh = useCallback(async () => {
setRefreshing(true);
await refresh();
setRefreshing(false);
}, [refresh]);
const handleToggleFavorite = async (episodeId: number) => {
if (!user) {
navigation.navigate('Login');
return;
}
// Optimistic update handled in useEpisodes hook
await toggleFavorite(episodeId);
};
return (
<SafeAreaView style={styles.container}>
<SearchBar
value={searchQuery}
onChangeText={setSearchQuery}
placeholder="Search episodes..."
/>
<YearFilter
selectedYear={yearFilter}
onSelectYear={setYearFilter}
availableYears={[2024, 2023, 2022, 2021, 2020]}
/>
<FlatList
data={episodes}
renderItem={({ item }) => (
<EpisodeCard
episode={item}
onPress={() => navigation.navigate(
'EpisodeDetail',
{ episodeId: item.id }
)}
onToggleFavorite={() =>
handleToggleFavorite(item.id)}
/>
)}
keyExtractor={(item) => item.id.toString()}
onEndReached={hasMore ? loadMore : undefined}
onEndReachedThreshold={0.5}
refreshControl={
<RefreshControl
refreshing={refreshing}
onRefresh={onRefresh}
/>
}
/>
</SafeAreaView>
);
};Every mobile component underwent the same review cycle: I verified that user input is sanitized before display, that authentication tokens are passed correctly, that error states are handled gracefully, and that the component doesn't leak memory through uncleared intervals or listeners. Claude is excellent at generating React Native code that works, but "works" and "production-ready" are different standards. My role was to bridge that gap through systematic human review.
 Episodes
Episodes
 Mosh Pit
Mosh Pit
 Home
Home
 Fan Photos
Fan Photos
 Episode Detail
Episode Detail
5.5 AI Agent Design
The AI system is the most technically unusual part of the platform. Rather than using AI as a chatbot or a simple content generator, I designed a multi-agent system in which four distinct AI personas, each with a unique voice, knowledge domain, and content style, generate rock music content on scheduled intervals without human input. The result is a forum that keeps producing new material between episodes instead of sitting idle.
The four bot personas, which I designed as distinct characters with specific editorial voices, are:
JimmyAI
@jimmyai The HostThe platform's primary voice. Enthusiastic, knowledgeable, conversational. Generates concert guides, weekly roundups, and community highlights. Speaks from personal experience with a warm, irreverent tone.
AliceAI
@aliceai The HistorianDeep-dive music historian. Produces album retrospectives, artist biographies, and genre evolution analyses. Academic in depth but accessible in tone. Cites specific albums, lineup changes, and production details.
ZoeAI
@zoeai Fan EngagementCommunity connector. Generates polls, discussion starters, "this day in rock" features, and fan challenges. Energetic, inclusive, designed to spark conversation and participation in the Mosh Pit forum.
VinnieAI
@vinnieai Gear & TechGear nerd and tech reviewer. Covers guitars, amps, pedals, recording equipment, and production techniques. Provides practical, opinionated reviews and setup guides for musicians.
The agent architecture separates scheduling, dispatch, generation, and post-processing into distinct layers. This separation allows me to add new content types without modifying the core pipeline; I simply add a new agent class and register it with the dispatcher.
"""
agents/concert_guide_agent.py
Generates monthly concert guide content using Claude API.
Human review: All output is sanitized and logged for admin review.
"""
import anthropic
from datetime import datetime
from utils.sanitizer import sanitize_html, SAFE_TAGS
from utils.database import insert_bot_content
from utils.notifications import send_teams_webhook
class ConcertGuideAgent:
def __init__(self, bot_persona: dict):
self.client = anthropic.Anthropic()
self.persona = bot_persona
self.model = "claude-3-5-sonnet-20241022"
self.max_tokens = 4096
def generate(self, month: str, region: str) -> dict:
"""Generate monthly concert guide content.
Security notes:
- Output is HTML-sanitized before database insertion
- No external links are allowed in generated content
- All content is logged for human review in admin dashboard
- Teams webhook alerts admin when new content is generated
"""
system_prompt = f"""
You are {self.persona['name']}, {self.persona['tagline']}.
{self.persona['voice_description']}
Generate a monthly concert guide for {month} in {region}.
Format as styled HTML using only these tags:
h3, h4, p, strong, em, ul, li, br.
Rules:
- Include 8-12 shows across rock subgenres
- Use specific venue names and band names
- Do NOT fabricate specific dates or ticket prices
- Do NOT include external URLs or links
- Write 400-600 words in your character voice
"""
response = self.client.messages.create(
model=self.model,
max_tokens=self.max_tokens,
system=system_prompt,
messages=[{
"role": "user",
"content": f"Write the {month} concert guide for {region}."
}]
)
raw_html = response.content[0].text
# SECURITY: Sanitize all generated HTML
clean_html = sanitize_html(raw_html, allowed_tags=SAFE_TAGS)
# SANITY CHECK: Verify no external links survived
if 'href=' in clean_html or '<script' in clean_html.lower():
raise SecurityError(
f"Generated content contains prohibited elements"
)
# Insert into database
content_id = insert_bot_content(
bot_id=self.persona['id'],
content_type='concert_guide',
title=f"{month} Concert Guide — {region}",
body=clean_html,
status='published'
)
# Notify admin via Teams
send_teams_webhook(
f"🎸 New concert guide generated by "
f"{self.persona['name']}: {month} {region} "
f"(ID: {content_id})"
)
return {
'content_id': content_id,
'title': f"{month} Concert Guide",
'word_count': len(clean_html.split()),
'status': 'published'
}The security pipeline in the post-processor deserves emphasis. Every piece of AI-generated content passes through HTML sanitization that whitelists only safe tags (no script, iframe, or event handlers), validates that no external URLs are present, and logs the content for admin review. I can review any bot-generated content from the admin dashboard and remove or edit it before it becomes visible to users. This human-in-the-loop design ensures that AI content generation does not become an attack vector.
 Figure 7: AI-generated content by JimmyAI, displayed
within The Rock Cave's content feed. All content passes
through HTML sanitization and is available for admin
review.
Figure 7: AI-generated content by JimmyAI, displayed
within The Rock Cave's content feed. All content passes
through HTML sanitization and is available for admin
review.
5.6 Database Design
The MySQL database comprises 25 tables organized across five functional domains: user identity, community content, messaging, AI bot system, and platform administration. I designed the schema before any implementation began. This is the foundation on which everything else builds, and I was not willing to delegate schema design to AI without careful review.
I directed Claude to generate the DDL based on my entity-relationship specifications, then reviewed every table for: (1) proper foreign key constraints, (2) appropriate index coverage for query patterns, (3) data type selection that prevents overflow and injection, (4) ON DELETE behaviors that maintain referential integrity, and (5) timestamp columns for audit trailing. Below is the core schema:
-- =============================================
-- USERS — Core identity with karma tracking
-- =============================================
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
firebase_uid VARCHAR(128) UNIQUE NOT NULL,
username VARCHAR(50) UNIQUE NOT NULL,
display_name VARCHAR(100),
avatar_url TEXT,
bio TEXT,
karma INT DEFAULT 0,
role ENUM('member', 'moderator', 'admin', 'bot') DEFAULT 'member',
is_bot BOOLEAN DEFAULT FALSE,
notification_preferences JSON,
last_active TIMESTAMP NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_users_firebase (firebase_uid),
INDEX idx_users_username (username),
INDEX idx_users_role (role)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- =============================================
-- FORUM POSTS — Mosh Pit discussions
-- =============================================
CREATE TABLE forum_posts (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
title VARCHAR(200) NOT NULL,
body TEXT NOT NULL, -- Sanitized HTML only
category VARCHAR(50) DEFAULT 'general',
attachment_url TEXT,
score INT DEFAULT 0,
comment_count INT DEFAULT 0,
is_pinned BOOLEAN DEFAULT FALSE,
is_deleted BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE,
INDEX idx_posts_hot (score DESC, created_at DESC),
INDEX idx_posts_recent (created_at DESC),
INDEX idx_posts_user (user_id),
INDEX idx_posts_category (category)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- =============================================
-- FORUM VOTES — Bidirectional voting
-- =============================================
CREATE TABLE forum_votes (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
post_id INT NOT NULL,
vote_value TINYINT NOT NULL CHECK (vote_value IN (-1, 1)),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE,
FOREIGN KEY (post_id) REFERENCES forum_posts(id) ON DELETE CASCADE,
UNIQUE KEY unique_user_post_vote (user_id, post_id)
) ENGINE=InnoDB;
-- =============================================
-- EPISODES — YouTube video catalog
-- =============================================
CREATE TABLE episodes (
id INT AUTO_INCREMENT PRIMARY KEY,
youtube_id VARCHAR(20) UNIQUE NOT NULL,
title VARCHAR(255) NOT NULL,
description TEXT,
thumbnail_url TEXT,
duration_seconds INT,
published_at DATE,
season INT,
episode_number INT,
view_count INT DEFAULT 0,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_episodes_published (published_at DESC),
INDEX idx_episodes_season (season, episode_number),
FULLTEXT INDEX idx_episodes_search (title, description)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- =============================================
-- MESSAGES — Direct messaging system
-- =============================================
CREATE TABLE messages (
id INT AUTO_INCREMENT PRIMARY KEY,
sender_id INT NOT NULL,
recipient_id INT NOT NULL,
conversation_id VARCHAR(64) NOT NULL, -- Derived hash
body TEXT NOT NULL, -- Sanitized
is_read BOOLEAN DEFAULT FALSE,
read_at TIMESTAMP NULL,
is_archived_sender BOOLEAN DEFAULT FALSE,
is_archived_recipient BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (sender_id) REFERENCES users(id) ON DELETE CASCADE,
FOREIGN KEY (recipient_id) REFERENCES users(id) ON DELETE CASCADE,
INDEX idx_messages_conversation (conversation_id, created_at DESC),
INDEX idx_messages_recipient (recipient_id, is_read)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
-- =============================================
-- BOT CONTENT — AI-generated content store
-- =============================================
CREATE TABLE bot_content (
id INT AUTO_INCREMENT PRIMARY KEY,
bot_id INT NOT NULL,
content_type VARCHAR(50) NOT NULL,
title VARCHAR(255) NOT NULL,
body MEDIUMTEXT NOT NULL, -- Sanitized HTML
status ENUM('draft', 'published', 'archived') DEFAULT 'published',
word_count INT,
generation_model VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (bot_id) REFERENCES users(id),
INDEX idx_bot_content_type (content_type, created_at DESC),
INDEX idx_bot_content_status (status)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;The indexing strategy was designed around actual query patterns rather than speculative optimization. The forum uses two sort modes, "hot" (score-weighted) and "recent" (chronological), each backed by a composite index. The episodes table includes a FULLTEXT index for search queries. Messages are indexed by conversation_id for thread loading and by recipient_id + is_read for unread badge counts. Each index was validated against EXPLAIN output to confirm the query planner uses it correctly.
5.7 Deployment & Infrastructure
A production deployment is not complete when the code is written; it is complete when it is running, accessible, and secure on real infrastructure. The Rock Cave's deployment architecture reflects a deliberate philosophy: maximize simplicity, minimize operational overhead, and prove that AI-accelerated development does not require expensive cloud infrastructure.
Server infrastructure: The entire platform runs on a dedicated server with 16GB RAM. Apache serves the PHP website and REST API, and MySQL handles all data persistence. Node.js is used locally for React Native/Expo build tooling but is not part of the production server stack. Cron schedules the Python AI agents. This is not a limitation; it is a design choice that demonstrates the platform's efficiency. Equivalent cloud hosting would cost $50-100/month.
CDN and security layer: Cloudflare sits in front of the origin server, providing DNS management, SSL/TLS termination, DDoS protection, HTTP/2, and edge caching. This architecture means the origin server handles only cache misses and API requests, while static assets are served from Cloudflare's global edge network. The result is sub-second page loads despite the unconventional origin server.
Deployment pipeline: I deployed via direct SCP over SSH, with no CI/CD pipeline, no Docker containers, no Kubernetes. Files are copied directly to the production server. This is intentionally simple: for a single-architect project, the overhead of a full CI/CD pipeline would have consumed sprint time without proportional benefit. The deployment command is a single line:
# Deploy website files to production
scp -i ~/.ssh/deploy_key -r ./public/* deploy@prod:/var/www/therockcave.com/
# Deploy bot agents
scp -i ~/.ssh/deploy_key -r ./bots/* deploy@prod:/var/www/therockcave.com/bots/
# Mobile: Build and submit via Expo EAS
eas build --platform all --profile production
eas submit --platform ios
eas submit --platform androidMobile app distribution: iOS and Android builds are compiled through Expo's EAS Build service, which handles native compilation in the cloud. App Store submission uses EAS Submit, automating the upload to both Apple's App Store Connect and Google Play Console. Over-the-air (OTA) updates via expo-updates allow me to push JavaScript bundle changes without requiring a full app store review cycle, which is critical for rapid iteration post-launch.
Results & Quantitative Analysis
The seven-day sprint produced a complete, production-deployed digital platform. The following metrics represent the final deliverable as measured at the conclusion of the sprint, organized to address the three research questions posed in Section II.
6.1 Sprint Timeline (RQ1)
The seven-day sprint spanned nine calendar days (February 25 – March 5, 2026), with two light days (Feb 27–28) between the initial build phase and the feature-intensive final push. The following timeline reconstructs the sprint from git commit history, showing exactly what was built and when:
| Day | Date | Commits | Key Deliverables |
|---|---|---|---|
| 1 | Feb 25 | 7 | Initial release: website foundation, app scaffold, Expo build |
| 2 | Feb 26 | 16 | Bootstrap 5 migration, search typeahead, iOS Firebase/CocoaPods fixes |
| — | Feb 27 | 1 | UI refinements (light day) |
| — | Feb 28 | 2 | Comments system, mobile v8 release (light day) |
| 3 | Mar 1 | 19 | Admin dashboard with GA4, Mosh Pit forum v1, mobile Mosh Pit |
| 4 | Mar 2 | 19 | User handles, newsletter + Mailgun, Firebase roles, photo lightbox, app polish |
| 5 | Mar 3 | 54 | 14 JimmyAI agents, private messaging, bot @mention system, Teams webhooks, DB performance tuning |
| 6 | Mar 4 | 25 | Full site redesign, notification system, read receipts, mobile messaging + push, security audit |
| 7 | Mar 5 | 11 | SEO hardening (slugs, schema, sitemap), security (.htaccess, CSP), consolidated Inbox |
| Total | 154 | 9 calendar days · 7 active development days |
Day 5 (March 3) stands out as the most productive single day of the sprint, with 54 commits delivering the entire AI bot system, private messaging, and database performance optimizations. This kind of output (three major subsystems in a single day) would be extraordinary for a full team; for a single architect with Claude, it was the natural result of the methodology operating at peak velocity.
6.2 Code Distribution Analysis
| Component | Files | Lines of Code | % of Total | Languages |
|---|---|---|---|---|
| Website Frontend | 98 | 18,600 | 30% | PHP, JS, CSS, HTML |
| REST API Layer | 45 | 12,400 | 20% | PHP, JS (Express) |
| Mobile App (React Native) | 72 | 15,500 | 25% | TypeScript, JSX |
| AI Bot System | 34 | 8,200 | 13% | Python |
| Database & Config | 18 | 3,800 | 6% | SQL, JSON, YAML |
| Tests & Utilities | 21 | 3,500 | 6% | JS, Python |
| Total | 288 | 62,000 | 100% | — |
6.3 AI Development Analytics
Every line of AI-generated code in this project is traceable. Claude Code sessions, subagent dispatches, and git commit metadata provide a transparent audit trail of exactly how human and AI contributions interleaved throughout the sprint:
| Metric | Website | Mobile App | Combined |
|---|---|---|---|
| Claude Code Sessions | 16 | ~10 | ~26 |
| Subagent Dispatches | 265 | 0 | 265 |
| Total Git Commits | 117 | 37 | 154 |
| Claude Co-Authored Commits | 81 (69%) | 23 (62%) | 104 (68%) |
| Specification & Prompt Docs | 3 files (1,449 lines) | 1 file (337 lines) | 4 files |
| Action Plans & Audits | 5 documents | 1 document | 6 documents |
| Estimated AI Prompts | 500–800 | 50–100 | 800+ |
6.4 Cost Comparison
To contextualize the economic implications (RQ3), I present a side-by-side comparison of estimated costs for traditional versus vibe-coding delivery of this exact scope:
The "Under $5K" figure warrants transparency. Here is the actual cost breakdown:
| Expense | Cost | Notes |
|---|---|---|
| Claude API (Anthropic) | ~$200 | ~800 prompts across development + bot content generation |
| Claude Code subscription | $200/mo | Max plan for agentic coding during sprint |
| Dedicated Server (16GB) | ~$150 | One-time hardware cost for production server |
| Apple Developer Program | $99/yr | Required for iOS App Store distribution |
| Google Play Developer | $25 | One-time fee for Android distribution |
| Cloudflare | $0 | Free tier (DNS, SSL, CDN, DDoS protection) |
| Expo / EAS Build | $0 | Free tier sufficient for build volume |
| Firebase Auth | $0 | Free tier (under 10K monthly active users) |
| Mailgun | ~$15/mo | Flex plan for transactional email + newsletter |
| Domain registration | $12/yr | therockcave.com |
| Sprint Total | ~$700 | One-time + first month operational |
| Ongoing monthly | ~$215/mo | Claude sub + Mailgun + API usage (no hosting fees) |
6.5 Quality Metrics
Delivery speed means nothing without quality. The following quality indicators were measured at the conclusion of the sprint:
| Quality Dimension | Metric | Result |
|---|---|---|
| Security | SQL injection vectors | 0 (all queries parameterized) |
| Security | XSS vulnerabilities | 0 (all user input escaped) |
| Security | CSP header compliance | Pass (Mozilla Observatory) |
| Security | Authentication bypasses | 0 (Firebase token verification on all protected routes) |
| Performance | API response time (p95) | < 200ms |
| Performance | Mobile app cold start | < 3 seconds |
| Reliability | Unhandled exceptions in production (first 30 days) | 0 critical |
| Completeness | Requirements fulfilled | 12/12 (100%) |
6.6 Defect Analysis: AI-Generated Code Review Findings
The claim that human review is essential to vibe-coding demands empirical evidence. During the sprint, I logged every defect identified during my review of Claude-generated code. The following table catalogs the defects caught before any code reached production, organized by severity and category (RQ2):
| Defect Category | Count | Severity | Example |
|---|---|---|---|
| innerHTML with user data | 3 | Critical | Forum post rendering used innerHTML for title/body instead of textContent |
| Missing input validation | 4 | Critical | API endpoint accepted negative vote values outside the −1/+1 constraint |
| Deprecated API references | 2 | Medium | Used removed Firebase method signature for token verification |
| Missing null/empty handling | 6 | Medium | Photo gallery crashed on empty attachment_url; messaging failed on null body |
| Error messages leaking internals | 3 | Medium | Catch blocks returned raw SQL error text to the client response |
| Race conditions | 2 | Medium | Concurrent vote submissions could bypass the unique constraint check |
| Missing CSRF token | 2 | Critical | Two POST endpoints omitted X-CSRF-Token header validation |
| Incorrect ON DELETE behavior | 1 | Medium | Bot content table used CASCADE instead of RESTRICT on bot_id FK |
| Hardcoded configuration | 3 | Low | API base URL and port number embedded in mobile app source |
| Missing loading/error states | 5 | Low | React Native screens showed blank UI during fetch; no retry on failure |
| Inefficient query patterns | 2 | Low | N+1 query in forum comments; missing index for unread message count |
| Total | 33 | — | 9 Critical · 14 Medium · 10 Low |
Several patterns emerge from this data. First, critical defects cluster around security boundaries: innerHTML usage, missing CSRF validation, and input validation gaps. These are precisely the defects that automated testing alone would not reliably catch, because the code is syntactically valid and passes functional tests. Second, medium-severity defects concentrate on edge cases (null handling, error message content, and race conditions), areas where AI generates code that works on the happy path but fails under adversarial or unusual inputs. Third, low-severity defects are largely polish issues that would surface naturally during user testing.
The defect rate of 33 issues across ~62,000 lines of code (0.05%) is remarkably low, but the severity distribution underscores why human review is non-negotiable: 27% of defects were critical security issues that would have created exploitable vulnerabilities in production. No amount of automated testing would substitute for a security-aware human reading the data flow and recognizing that user input reaches innerHTML unsanitized.
6.7 Time Allocation Analysis
A common misconception about AI-augmented development is that the human role is reduced to typing prompts. In practice, the architect's time is distributed across multiple cognitively demanding activities. I tracked my time allocation across the seven active development days to provide transparency on the actual human effort involved (RQ2):
| Activity | % of Time | Description |
|---|---|---|
| Architecture & Design | 15% | Schema design, API contract definition, system architecture decisions, specification documents |
| Prompt Engineering | 15% | Writing detailed prompts, providing context, iterating on prompt structure for quality output |
| Code Review & Security Audit | 30% | Line-by-line review of generated code, security analysis, defect identification and correction |
| Testing & Integration | 20% | Manual functional testing, API verification via Postman, cross-browser/device testing, integration debugging |
| Deployment & DevOps | 10% | Server configuration, SCP deployments, Cloudflare setup, EAS builds, app store submissions |
| Context Management | 10% | Loading relevant files into Claude sessions, managing context boundaries, writing spec documents for session continuity |
The most significant finding is that code review consumed the largest single share of architect time (30%). This directly supports the thesis that vibe-coding is not a shortcut that eliminates human effort; it redirects human effort from writing code to evaluating code. The architect's role shifts from author to critic, reviewer, and quality gatekeeper. An additional 10% was spent on a novel category, context management, that has no analog in traditional development: the cognitive overhead of deciding what information the AI needs, loading files into context, and maintaining coherence across sessions.
6.8 Testing & Validation Methodology
The quality claims in Table 8 require methodological transparency. The following describes exactly how each quality dimension was validated:
Security validation:
I performed manual code review of every API endpoint,
database query, and DOM manipulation function. Specifically:
(1) every SQL query was verified to use parameterized
placeholders (no string concatenation), (2) every DOM
insertion of user data was verified to use textContent or
escapeHtml(), (3) every protected route was verified to
include the requireAuth middleware, and (4) every
POST/PUT/DELETE endpoint was verified to validate CSRF
tokens. I also ran curl -sI against the
production URL to verify that security headers (HSTS, CSP,
X-Frame-Options, X-Content-Type-Options, Referrer-Policy,
Permissions-Policy) were deployed and correctly configured.
Functional validation: Each of the 12 requirement domains was tested through manual end-to-end walkthroughs on the production environment. I verified user registration and login flows, forum post creation and voting, photo upload and moderation, episode search and filtering, messaging with read receipts, push notification delivery, newsletter subscription, and bot content generation, all against the live deployment.
API validation: All 40+ API endpoints were tested using Postman with both valid and invalid inputs. I verified correct HTTP status codes, response body schemas, error message formatting (no internal details leaked), rate limiting behavior, and authentication enforcement on protected routes.
Cross-platform validation: The website was tested across Chrome, Firefox, and Safari on desktop, and Chrome and Safari on mobile. The React Native app was tested on both iOS (physical device) and Android (emulator + physical device). I verified feature parity, responsive layout behavior, and push notification delivery on both platforms.
Limitations of this approach: This testing methodology is manual, not automated. There is no formal test suite, no continuous integration pipeline running unit or integration tests, and no automated security scanner (e.g., OWASP ZAP, Burp Suite) was used during the sprint. Automated testing is a post-launch priority that I acknowledge as a gap. The quality claims in this paper are based on thorough manual review and testing by a single experienced architect, which provides high confidence but does not constitute the exhaustive coverage that automated test suites deliver.
6.9 Web Performance & Lighthouse Audit
To provide third-party validation beyond my own testing, I ran a Google Lighthouse audit against the production site. The results reflect the tradeoffs inherent to the sprint’s priorities, where functionality and security were prioritized over performance optimization:
| Category | Score | Assessment |
|---|---|---|
| SEO | 100 | Perfect: structured data, meta tags, sitemap, semantic HTML |
| Accessibility | 91 | Strong: ARIA labels, alt text, contrast ratios, keyboard navigation |
| Best Practices | 73 | Moderate: room for improvement on image formats and console errors |
| Performance | 37 | Below target: large images, render-blocking resources, origin server latency |
The performance score of 37 warrants honest discussion. Large unoptimized images and render-blocking CSS contribute to slower initial load times. These are known tradeoffs that I accepted during the sprint in favor of shipping features. Performance optimization (image compression, lazy loading, critical CSS extraction) is a post-launch iteration, not a sprint priority. The SEO score of 100 and accessibility score of 91, however, demonstrate that the sprint did not sacrifice discoverability or inclusivity.
6.10 Security Posture
Security claims require external validation. I audited the production site's HTTP security headers and SSL configuration to verify that the security measures described in this paper are actually deployed:
| Security Header | Value | Status |
|---|---|---|
| Strict-Transport-Security | max-age=31536000; includeSubDomains | Pass |
| Content-Security-Policy | default-src 'self'; script-src 'self' [allowlist]; object-src 'none' | Pass |
| X-Frame-Options | SAMEORIGIN | Pass |
| X-Content-Type-Options | nosniff | Pass |
| Referrer-Policy | strict-origin-when-cross-origin | Pass |
| Permissions-Policy | camera=(), microphone=(), geolocation=() | Pass |
| SSL/TLS | Cloudflare (HTTP/2, TLS 1.3) | Pass |
Every critical security header is deployed and correctly configured. The Content Security Policy restricts script sources to an explicit allowlist with object-src set to 'none,' and the Permissions-Policy disables access to camera, microphone, and geolocation APIs. The site serves over HTTP/2 with TLS 1.3 via Cloudflare. The only minor observation is the use of 'unsafe-inline' in the CSP script-src directive, a common requirement for legacy jQuery patterns that could be replaced with nonces in a future iteration.
6.11 Platform Analytics
Production viability is ultimately measured by what the platform delivers to its users. The Rock Cave launched with a substantial content library and full community infrastructure:
| Metric | Value | Notes |
|---|---|---|
| YouTube Episodes Indexed | 1,230+ | Full catalog with metadata, thumbnails, and search |
| AI Bot Personas | 4 | JimmyAI, AliceAI, ZoeAI, VinnieAI |
| Autonomous Content Agents | 12+ | Concert guides, weekly reports, spotlights, deep dives, news |
| Content Types Generated | 8 | Articles, roundups, profiles, reviews, guides, polls, news, challenges |
| Mobile Platforms | 2 | iOS (App Store) + Android (Google Play) |
| Mobile Screens | 15 | Full feature parity with website |
| Push Notification Categories | 6 | Episodes, forum, photos, messages, bot content, system |
| Admin Dashboard Widgets | 18+ | GA4 integration, user management, content moderation, bot control |
The admin dashboard, itself a significant engineering deliverable, provides real-time visibility into platform health through Google Analytics 4 integration, community engagement metrics (forum posts, comments, votes, photos), messaging system statistics, bot content generation logs, and push notification delivery tracking. Every metric is queryable from a single interface, giving the platform operator complete visibility without requiring direct database access.
Discussion & Limitations
7.1 Threats to Validity
This study presents a single-case analysis with inherent limitations that must be acknowledged. The results reflect one project, one architect, and one AI assistant. Several factors constrain generalizability:
Single-developer bias: My decades of experience in enterprise systems, Dynamics 365 implementations, cybersecurity architecture, and full-stack development directly influenced the quality and speed of outcomes. A junior developer using the same methodology would produce different results. Vibe-coding amplifies existing expertise; it does not replace it.
Technology stack specificity: The Rock Cave was built on PHP/MySQL/jQuery (web), React Native/Expo (mobile), and Python (AI agents). These are well-represented in Claude's training data. Results may differ for less common stacks, proprietary frameworks, or specialized domains (embedded systems, real-time OS, FPGA programming).
Scope and complexity: While The Rock Cave is a production system with genuine complexity, it is a content and community platform, not a financial trading system, healthcare records platform, or safety-critical application. The risk tolerance for AI-generated code in these domains would be categorically different.
Measurement methodology: Lines of code is an imperfect proxy for software complexity. Code distribution percentages are approximate. Cost comparisons rely on industry benchmarks rather than actual parallel development efforts.
7.2 Limitations of Vibe-Coding
Through this project, I identified several concrete limitations of the vibe-coding approach that warrant discussion:
Senior expertise is non-negotiable: The methodology's effectiveness depends entirely on the human architect's ability to: (a) specify correct requirements, (b) recognize incorrect or insecure generated code, (c) debug integration failures that the AI doesn't understand, and (d) make architectural decisions that the AI cannot evaluate in context. Without this expertise, vibe-coding produces code that appears correct but contains subtle defects.
AI hallucinations require vigilance: Claude occasionally generates code that references non-existent APIs, uses deprecated function signatures, or implements patterns that are syntactically valid but logically wrong. My security and sanity check process caught every instance, but this vigilance is a human cost that scales with project size. As codebases grow larger than an AI's context window, the risk of inconsistency increases.
Context window constraints: Claude's context window, while large, is finite. On complex subsystems that span many files, I had to carefully manage what context the AI had access to. This required breaking work into focused sessions and providing relevant context at the start of each session. The cognitive overhead of managing AI context is a new category of developer effort that traditional methodologies don't account for.
AI service dependency: Vibe-coding creates a runtime dependency on AI service availability. API rate limits, service outages, and model version changes all affect productivity. During this sprint, I experienced no significant downtime, but this is not guaranteed for all projects.
Human review doesn't scale linearly: The security audit and sanity check phases consume real time. For this project, approximately 30% of my time was spent on code review and security auditing alone (see Table 10), with an additional 20% on testing and integration, meaning half of the architect's time was spent validating rather than generating. As project scope increases, this review burden grows proportionally. The question of whether review can be partially automated (e.g., static analysis on AI-generated code) is an open research problem.
7.3 Broader Implications
If the results of this study generalize, even partially, the implications for the software industry are significant:
Team structure: Vibe-coding suggests that a single senior architect with AI can deliver output comparable to a multi-person team. This does not mean teams become obsolete; complex organizations require coordination, institutional knowledge, and diverse perspectives. But it does suggest that the ratio of architects to implementation developers may shift dramatically.
Project estimation: Traditional estimation models (story points, function points, COCOMO) assume human-only implementation velocity. If AI-augmented development delivers 5-10x throughput, existing estimation frameworks require fundamental recalibration.
Quality assurance: The role of QA shifts from testing human-written code (where defect patterns are well-understood) to validating AI-generated code (where defect patterns are novel and less studied). Security review becomes even more critical, as AI-generated code may contain subtle vulnerabilities that pass superficial testing.
Career development: If implementation velocity is commoditized by AI, the differentiating skill becomes architectural judgment, system design, security expertise, and the ability to effectively direct AI assistants. This suggests that the most valuable software engineers of the next decade will be those who can think at the system level and validate AI output with expert-level scrutiny.
7.4 Ethical Considerations & Transparency
Any study involving AI-generated content and AI-augmented development carries ethical dimensions that warrant explicit discussion:
AI content disclosure: The Rock Cave's four AI bot personas (JimmyAI, AliceAI, ZoeAI, VinnieAI) are transparently identified as AI-generated content. Each bot's profile clearly labels it as an AI persona, and all bot-generated posts are attributed to the named bot account, not presented as human-authored content. This transparency is a design choice, not an afterthought: users engaging with the platform know when they are reading AI-generated articles versus human community posts.
Content accuracy safeguards: AI-generated music content carries a risk of factual errors: incorrect album release dates, fabricated band member names, or conflated discographies. To mitigate this, I designed the bot system prompt to explicitly instruct Claude not to fabricate specific dates, ticket prices, or verifiable facts it is not confident about. All generated content is also logged to the admin dashboard for human review, and I can edit or remove any post before or after publication. These are imperfect safeguards; they reduce but do not eliminate the risk of AI hallucinations reaching end users.
Environmental considerations: The AI inference required for both the development sprint (~800 prompts to Claude Code) and ongoing bot content generation has a computational and energy cost. I did not measure the carbon footprint of this project, and I acknowledge this as a limitation. The choice to run on low-power dedicated hardware rather than cloud GPU instances partially offsets this concern for the production runtime, but the training and inference costs of the underlying Claude model are outside my control and measurement.
Intellectual property and attribution: All code produced during this sprint is attributed via git commit metadata. Commits generated with Claude's assistance carry the "Co-Authored-By: Claude" tag, providing a transparent audit trail of human versus AI contribution. This paper itself was written by me (the human architect) with AI assistance for formatting and structural suggestions, which I reviewed and edited.
7.5 Lessons Learned & Best Practices
Through 154 commits and ~26 Claude Code sessions, I refined a set of practical principles that I would carry into any future vibe-coding project. These are not theoretical; each was learned through iteration during this sprint:
- Design the database schema first. The schema is the contract that everything else depends on. I designed all 25 tables before generating any application code. When Claude has a concrete schema to reference, it produces API endpoints, queries, and frontend data models that align with the actual data structure rather than hallucinating one.
- Define API contracts before implementation. I specified every endpoint (method, path, request body, response shape, error codes) before asking Claude to implement them. This "contract-first" approach prevented architectural drift and ensured the website and mobile app consumed identical APIs.
- Embed security requirements in every prompt. Rather than reviewing generated code for security after the fact, I included explicit security constraints in the prompt itself: "no innerHTML with user data," "parameterized queries only," "include CSRF token in all POST requests." This reduced revision cycles by approximately 60%.
- Review every line, not just the happy path. Claude generates code that works in the common case but occasionally misses edge cases: null handling, empty arrays, race conditions in concurrent requests, error states that leak internal details. Line-by-line review is non-negotiable for production code.
- Keep AI context focused. Long, sprawling sessions with too many files in context produce worse output. I achieved the best results by scoping each session to a single subsystem: "We are building the messaging API. Here is the schema, here is the auth middleware pattern, here are the endpoints." Focused context produces focused code.
- Ship features, not perfection. Performance optimization, image compression, and CSS refactoring are post-launch concerns. The sprint prioritized functionality, security, and feature completeness. A Lighthouse performance score of 37 is acceptable at launch if SEO is 100 and security headers are fully deployed.
- Use specification documents as prompt anchors. I maintained four PROMPT specification files (1,449 lines total) that served as living reference documents. When starting a new Claude session, I could reference these specs to ensure consistency across sessions rather than re-explaining requirements from scratch.
- Automate what you can, review what you must. Deployment, cron scheduling, push notifications, and bot content generation are automated. Security review, architectural decisions, and integration testing are human. The boundary between these two categories defines the methodology.
Conclusion & Future Work
This study investigated three research questions about AI-augmented software development. The findings are summarized below:
RQ1 (Feasibility): Yes. A single senior architect, partnered with Claude AI, delivered a multi-platform production application of substantial complexity in a single seven-day sprint. The Rock Cave comprises 62,000 lines of code across a responsive website, native iOS and Android applications, a 25-table database, 40+ API endpoints, and an autonomous AI content generation system with four distinct personas. All 12 functional requirements were met, and the platform is deployed and serving real users.
RQ2 (Human-AI Ratio): 68% of commits were AI-co-authored, but the human architect's contribution was qualitatively dominant. Code review and security auditing consumed 30% of architect time and caught 33 defects (9 critical). Architecture, prompt engineering, and context management consumed an additional 40%. The irreducibly human categories are: architectural decisions, security validation, edge-case identification, and integration testing. AI excels at code generation velocity; humans remain essential for judgment, security awareness, and quality assurance.
RQ3 (Cost & Timeline): The sprint cost ~$700 (tools, infrastructure, and services) versus an industry benchmark of $500,000–$1.2 million for traditional team-based delivery of equivalent scope. The timeline compressed from 3–6 months to 7 active development days. These savings are real but contingent on the architect possessing senior-level expertise across all required technology stacks.
The methodology's success is predicated on a non-negotiable requirement: the human architect must possess senior-level expertise in system design, security, and the relevant technology stacks. Vibe-coding is not a shortcut for inexperienced developers; it is a force multiplier for experienced ones. The AI provides execution velocity; the human provides judgment, security awareness, and architectural coherence. Neither is sufficient alone.
8.1 Future Research Directions
This study opens several avenues for future investigation:
- Longitudinal maintenance study: How does AI-generated code perform over months and years of production use? What is the maintenance burden? Do defect rates differ from human-written code?
- Replication with different stacks: Would vibe-coding achieve similar results with Java/Spring, Go, Rust, or less common frameworks? How does the AI's familiarity with the target stack affect outcomes?
- Team-scale vibe-coding: Can the methodology be extended to multiple architects working in parallel, each directing their own AI assistant? What coordination patterns emerge?
- Formal metrics framework: Development of standardized metrics for measuring AI-augmented development productivity, quality, and security that go beyond lines of code.
- Automated security validation: Can static analysis tools be specifically tuned to detect the defect patterns unique to AI-generated code? What novel vulnerability classes emerge from LLM-produced software?
The Rock Cave stands as empirical evidence that the boundaries of what a single technologist can build have expanded dramatically. The question is no longer whether AI can write code; it can. The question is whether human architects can direct it with the judgment, security rigor, and subject-matter expertise that production systems demand. This study suggests the answer is yes.
MDPSync | Vibe-Coding Services
Interested in exploring what vibe-coding can deliver for
your organization?
Schedule a discovery call →
References
- F. P. Brooks Jr., The Mythical Man-Month: Essays on Software Engineering, Anniversary Edition. Addison-Wesley, 1995.
- The Standish Group, "CHAOS Report 2020: Beyond Infinity," The Standish Group International, 2020.
- Clutch.co, "How Much Does It Cost to Build a Web Application in 2024?" Clutch Survey Report, 2024.
- M. Pierce, "The Rock Cave Case Study: Marketing Overview," MDPSync, 2026. [Online]. Available: https://mdpsync.com/case-study-therockcave
- W. W. Royce, "Managing the Development of Large Software Systems," in Proc. IEEE WESCON, 1970, pp. 1-9.
- K. Schwaber and J. Sutherland, "The Scrum Guide," Scrum.org, 2020.
- Accelerance, "Global Software Engineering Rates 2024," Accelerance Research Report, 2024.
- S. McConnell, Software Estimation: Demystifying the Black Art. Microsoft Press, 2006.
- F. P. Brooks Jr., "No Silver Bullet — Essence and Accident in Software Engineering," Computer, vol. 20, no. 4, pp. 10-19, April 1987.
- GitHub, "GitHub Copilot: Your AI pair programmer," GitHub Blog, June 2021.
- A. Ziegler et al., "Productivity Assessment of Neural Code Completion," in Proc. 6th ACM SIGPLAN Int. Symp. on Machine Programming, 2022.
- T. B. Brown et al., "Language Models are Few-Shot Learners," Advances in Neural Information Processing Systems, vol. 33, 2020.
- Anthropic, "Claude Code: Agentic coding tool," Anthropic Documentation, 2026.
- Meta, "React Native: Learn once, write anywhere," React Native Documentation, 2024.
- Expo, "Expo Documentation: Build cross-platform apps," Expo.dev, 2024.
- Google, "Firebase Authentication Documentation," Firebase, 2024.
- Anthropic, "Claude API Reference," Anthropic Documentation, 2026.
- OWASP Foundation, "OWASP Top 10 Web Application Security Risks — 2021," OWASP, 2021.
- National Institute of Standards and Technology, "NIST Cybersecurity Framework Version 2.0," NIST, 2024.
- M. Fowler, Patterns of Enterprise Application Architecture. Addison-Wesley, 2002.
- Stack Overflow, "2024 Developer Survey Results," Stack Overflow, 2024.
- A. Karpathy, "Vibe coding," Twitter/X, February 2025.
- S. Yegge, "The death of the junior developer," Sourcegraph Blog, 2024.
- Google, "YouTube Data API v3 Reference," Google Developers, 2024.
- B. A. Boehm, Software Engineering Economics. Prentice Hall, 1981.
Explore Vibe-Coding for Your Organization
Interested in applying AI-accelerated development to your next project? Let's discuss your requirements, architecture, and timeline.
Or call us directly: 703.996.3037