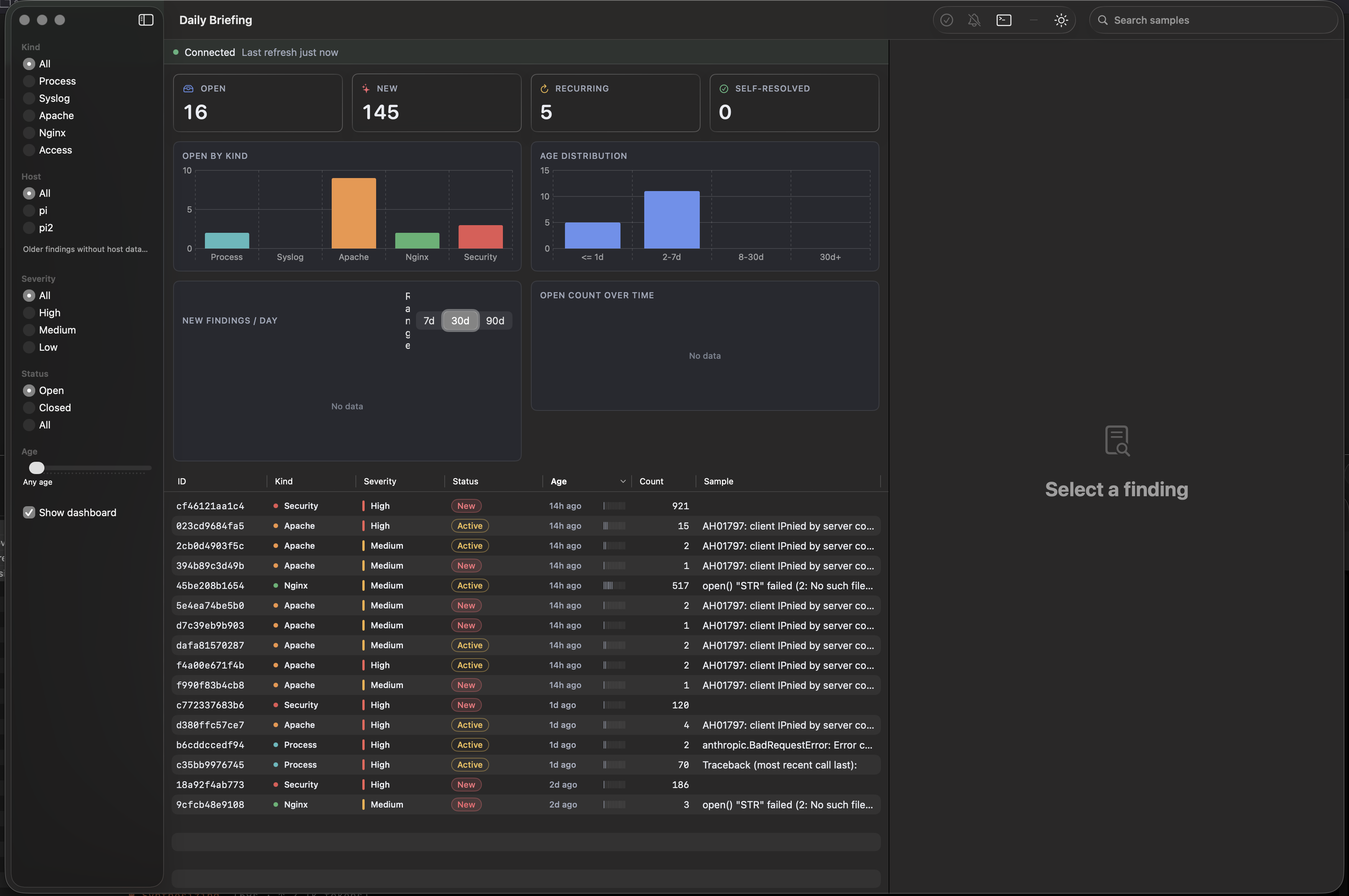
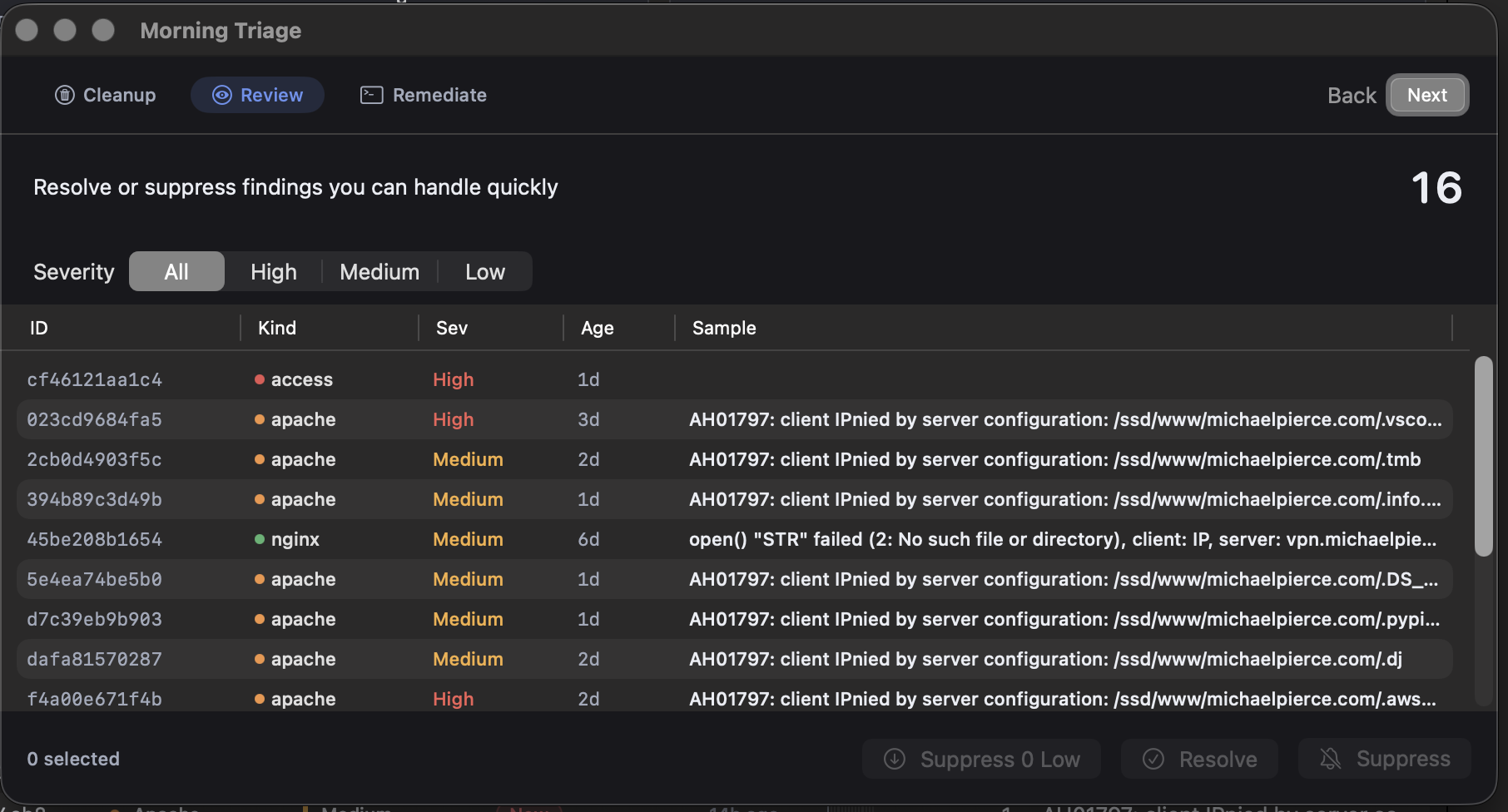
Eight Days of Receipts
The easy version of this story is "I shipped a dozen fixes in
a week." That is true, and it is also not very useful, because
the whole point is the receipts. The findings database has
been running since April 16. Here is what eight days of
production looks like.
Where the work actually happened
Access logs dominate raw volume because public-facing web
servers get scanned constantly, and almost all of that volume
ends up suppressed as noise. Syslog is the cleanest channel
because the classifier and I agree on what matters in it.
| Log kind |
Findings |
Resolved |
Suppressed |
Open |
| access |
760 |
214 |
463 |
83 |
| syslog |
277 |
250 |
27 |
0 |
| process |
82 |
11 |
69 |
2 |
| apache |
66 |
12 |
45 |
9 |
| nginx |
5 |
2 |
2 |
1 |
Syslog closed 250 of 277 findings with zero open. Access logs
carry 64% of total volume, most of it recon traffic getting
caught by suppress rules.
HIGH severity, up close
The classifier flagged 10 HIGH findings that turned out to be
real and got fixed. It flagged another 7 that were scanner
noise misclassified as high, which I suppressed once the
pattern was obvious. That leaves 15 HIGHs still open, which I
spent this morning reading. They cluster neatly into four
groups, and writing them down here is the kind of thing I
would have had no practical way to do a month ago.
Auth brute force. 8 findings, around 1,395 hits.
All auth_brute on pi2, spread across vhosts. The biggest
single burst was 921 hits on adultwidescreenwallpapers.com on
April 23. Recurring bursts landed on gulliblellama.com (three
separate findings totaling 238 hits), therockcave.com (102),
and a long tail of smaller 42-to-46-hit findings on April 24.
Almost certainly the same bot sweeping every vhost in order.
Next action is verifying the fail2ban apache-auth jail is
active on pi2. If it is, the suppress rule writes itself, and
the card stays clean without going blind to new patterns.
Apache config denials. 2 findings.
A .vscode path probe on michaelpierce.com, 20 hits over four
days and still active. A .aws/credentials probe, two hits,
textbook credential scraping. Apache is correctly returning
403 on both. The server is already doing the right thing, so
these get suppressed with a note about why.
Process errors. 2 findings.
Anthropic API credit exhaustion inside
therockcave/backfill.log, along with a 70-occurrence traceback
from the same exhaustion. Both from April 21-22. The backfill
has since completed, so these resolve with a note tying them
to the credit event so the history carries the cause.
Access anomalies. 3 more.
An api_abuse burst on therockcave.com, 120 hits on April 22. A
scanner_ua burst on haunts.michaelpierce.com, 186 hits on
April 21. One-off events from days ago. These resolve as
acknowledged.
None of this is glamorous. It is exactly the kind of long-tail
triage that used to stay invisible inside syslog forever. Now
it has a ticket, a history, and a next step that fits in a
sentence.
Time to resolve
Syslog closes fastest because the signal is strong and the
action is usually obvious. Apache and nginx take longer
because they need a browser tab open and a few minutes of
investigation before anything changes, which is what those
channels are for.
| Kind |
Avg |
Min |
Max |
| syslog |
8.9h |
4h |
9h |
| access |
13.2h |
7h |
16h |
| process |
47.3h |
7h |
53h |
| apache |
68.8h |
5h |
98h |
| nginx |
71.5h |
3h |
140h |
The suppress-rule payoff
Four operator-curated suppress rules are blocking 260 findings
before they ever reach the classifier. Two rules do most of
the work. One is recon_path combined with a 404 response,
catching 115 hits of scanner probing. The other is php_probe
combined with a 404 response, catching 145 hits of the same.
Recon and PHP probe traffic accounts for 695 of 760 access
findings, and the suppress engine handles 260 of those before
anything reaches a Teams card or an API call, which is the
behavior I want.
Who actually closes the findings
Of 1,167 resolution actions, the Mac app drove 840 of them. A
bulk data-repair pass accounts for another 253. I closed 60 by
hand. Operator-mode automation handled 14. Seven Mac-app
remediation sessions left full transcripts behind, and the
longest one ran roughly 12 minutes on a process-log finding,
producing about 50KB of reasoning before landing on a fix.
Ramp-up timeline
April 16 through April 18 was bootstrap. Forty-eight findings,
mostly syslog and process logs. April 19 through April 23 was
the big ramp once the access-log briefing went live, and 1,105
findings landed in five days. April 24 is already settling to
37 new findings for the day, which tells me the suppress rules
and the initial triage pass are converging on a steady state.
The Bottom Line
92% action rate, sub-day mean-time-to-resolve on syslog, four
suppress rules blocking 260 findings of scanner noise at the
door, ten HIGH findings actually fixed, and fifteen open HIGHs
with a next action written against each one.